The Architecture of Tokura.app
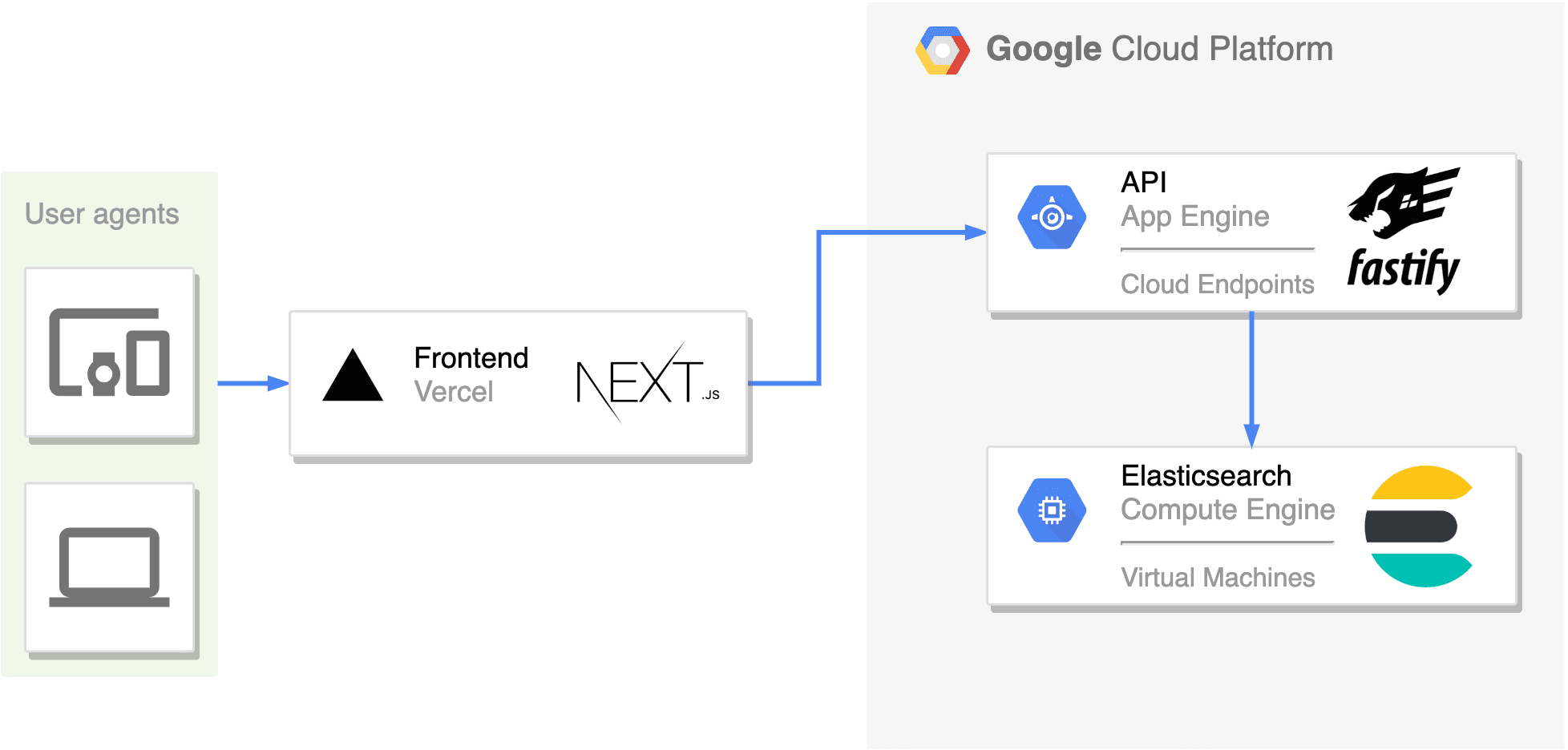
匿ラのあの回 (opens in a new tab) is a search engine specialized for 匿名ラジオ (opens in a new tab). The architecture behind it is simple. It consists of a frontend, an API, and a DB. That's all.
The frontend is built with Next.js deployed on Vercel. Vercel's CI/CD experience is astonishingly pleasant. Also I've chosen Tailwind CSS.
The API service framework is fastify. I want it to be fast enough for instant search experience, and indeed it is. It responds in around 50 ms on average. The service runs on GAE.
For both of the frontend and the API, I've written in TypeScript. The entire project is tiny but static typing helps me a lot over time. I forget what I did a week ago.
Behind the API service, Elasticsearch is there, a kind of document oriented database, running on a GCE instance. Its instance class is e2-small. E2-micro has too small RAMs for Es.
The data in Es is collected from YouTube using Data API v3. To be honest, collecting data is the hardest part of this project. The ETL (extract, transform, load) process still needs human operations, but partly automated. There is a room for improvement.
Beyond architecture
In my opinion, the core of this project is domain knowledge. The videos they make are very high context. People who's tried tokura.app say, "wow this is the thing I've ever wanted," "I've got ridiculously accurate search results." Those are not only what I wanted to hear, but what I expected to hear, because I myself have wanted this search engine for a long time. I love the creators so much that it was straightforward to me what to prepare and how to tune results. This time the solution was as clear as the problem.
© Nakayama Daichi.RSS